サポートベクトル識別機ノート
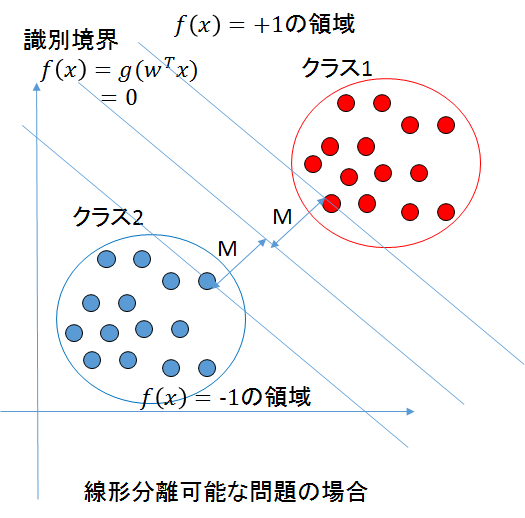
最大マージン分類機
2クラス問題を考える。
説明変数xiに対して目標(目的)変数yiがデータとして存在するとする。学習データの集合{(yi,xi)}、
i=1,⋯,Nを識別することを考える。(図はWikipediaより)
SVMは、原初的には、多次元空間のベクトル(点)データを平面で分割するスキームである。
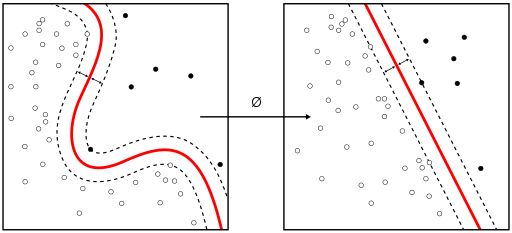
上の右図のように、境界が平面であればそのままでよいが、左のように境界が曲がっている可能性がある場合は、平面になるように変換する必要がある。その関数をϕと書く。左の図がxの空間で、右がϕの空間であると考えれば良い。
そうすると、次のような線形識別問題なる。
(図は、https://qiita.com/pesuchin/items/c55f40b69aa1aec2bd19 より引用)
別のページにプログラムを付属して解説するが、sciki-learnのsvm計算の具体例を以下に載せる。
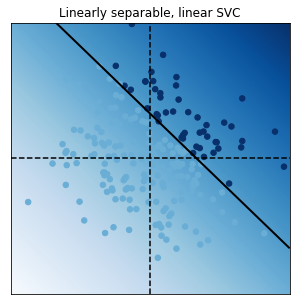
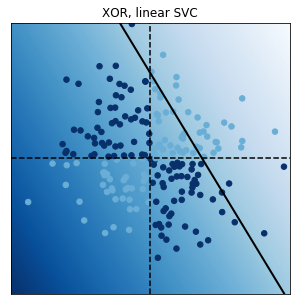
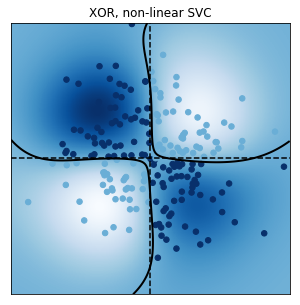
非線形な変換を施した説明変数ϕに対して目標変数が
y(xi)=k=1∑wkϕk(xi)+b
のように線形な関係で表されるとして、係数を{wi∣i=1,⋯M}を学習により決める。(以下ではまとめてベクトルwで表す。ここでの添字iはベクトルのi成分ではなく、データの番号を表すことに注意してほしい。)
このような{ϕ1(x),ϕ2(x),⋯,ϕM(x)}を「基底関数」という。以下、これを太字ϕで表す。
説明変数{x1,x2,⋯,xM}の非線形関数ϕを用いれば、うまく平面の境界が得られると想定している。
分類問題なので、f(x)の値によって±1をとる変数tiを目標変数となるように変換しておく(正規化):
- ti=1のときwTϕi+b≥1
- ti=−1のときwTϕi+b≤1
まとめると、すべてのデータについて
ti(wTϕi+b)≥1(1)
が成り立てば分類が成功だと判断できる。このとき等号が成り立つ場所が境界線で、それに近い一定の幅(マージン)上にあるデータをサポートベクトルと呼ぶ。
(境界から離れているので計算の対象としなくてよい。)
係数wを過学習にならなく、かつ最適な値になるように決める。具体的には
式(1)の制約のもとで
Lp(w)=21wTw
が最小となるwを求める。(マージンが最大になる。)
ラグランジュ未定定数法を用いると、未定定数をα1,⋯,αMとして
Lp~(w)=21wTw−i=1∑Nαi{ti(wTϕi+b)−1}(2)
の条件なし極値問題を解くことになる。
wの微係数がゼロという条件は
w−i=1∑Nαitiϕi=0(3)
bでの微分がゼロという条件は
i=1∑Nαiti=0(4)
となる。(他の条件の詳細は省く。)これにより、はじめにほしかった係数wがきまる。ただし、このときαがパラメータとして入っている。
(2)式を(3)に代入して、整理すると目的関数はαを変数として
Ld(α)=i=1∑Nαi+21i=1∑Nj=1∑Nαiαjtitjk(ϕi,ϕj),k(ϕi,ϕj)=ϕiTϕj
と表される。これを最小にするαを求める問題に置き換わったのである。
このk(ϕi,ϕj)をカーネルと呼ぶ。(カーネルはSVMに限らずもっと広く機械学習の手法で登場する。ただし定義は同じである。)
ϕiは、もともとの説明変数xiの非線形変換ϕi=ϕ(xi)であったとことに注意しよう。カーネルは2つのϕの積になっているが、そのことを忘れ(遡らず)、i, jの添字をもつベクトルからなる行列とみて、この極値問題を考えることにする。(かってにk(ϕi,ϕj)を選んだときにも、それに対応する非線形変換関数が存在することは証明されているらしい。)
そこで、もとの変数xを用いてk(x,x′)のように書くことができる。(もちろん単純な積ではない。カーネルは2つの特徴ベクトルの関数であるというだけである。)
Ld(α)=i=1∑Nαi+21i=1∑Nj=1∑Nαiαjtitjk(xi,xj)
カーネル関数は、原理的に導けるものではなく、良いものを選べばよいという立場で考えていく。(このような行き方はカーネルトリックと呼ばれる。)
多くの場合、2つのベクトルの距離∣∣x−x′∣∣の関数を選ぶのが妥当とされている。距離の関数なのでradial basis kernel(RBF)と呼ばれる。また、近い点ほど関係が深いとして関数としてはガウシアンがよく用いられる。
k(x,x′)=exp(−γ∣∣x−x′∣∣2)
これがガウシアンカーネルである。カーネルとして、べき関数やロジスティック関数が用いらることもあるようだ。
重要な点は、必要な非線形変換ϕ(x)を指定しなくてもカーネルを適当に定めて、境界線を引けるということである。
新しいデータ点f(x)を分類するには、カーネルと学習によって得られた係数を用いて
y(x)=n=1∑Nantnk(x,xn)+b
のように表される。改めて、最初に仮定した非線形変換(基底の変更)
ϕ(x)
がどのようなものかが表に現れなくなっていることに注意しよう。結果はうまく分類できたが最初の非線形変換ϕ(x)は意味がなくなった、原理的には存在するが、それを明示的に求める手法はない(必要ないから求めない)といっても良いと思う。
境界付近でデータが入り組んでいる場合:スラック変数の導入
多くの場合は、境界を明確に線引きできず、データは入り組んでいる。逆の領域に入り込んだ変数の対してスラック変数
ξn
を付与することにより、スラック変数の全体和が小さくなるような変分問題を考える。
Cn=1∑Nξn+21∣∣w∣∣
両者の重み付けパラメータCは、問題に応じて外から与える必要がある。
scikit-learnを用いた事例研究
http://8tops.yamanashi.ac.jp/~toyoki/labTips/dataScience/svc_in_scikit-learn.html
あわせて、多項式関数近似を参考にしてほしい。
http://8tops.yamanashi.ac.jp/~toyoki/labTips/dataScience/polynomial_fitting.html