サポートベクトルマシーン回帰 (SVR) メモ
サポートベクトルは分類機としてもちいられてきた(SVC)が、回帰にも応用できる。
ここでは、前節と同様にPRMLテキストをもとに、SVRについて簡単に解説する。
目的変数y、説明変数{xn}の関係を、非線形関数ϕ(xn)を用いて (ここでnはn番目のデータを表す)
yn=y(xn)=ωTϕ(x)
と表されるとする。ω, ϕの次元(要素数)は場合による。
観測値tnと予測値ynとの差が小さくなるようにwnをきめる。つまり、
21n=1∑N{yn−tn}2+2λ∣∣w∣∣2
「疎な解」を得るため(ほとんどのデータは予測値とほぼ同じと考え)、第1項の2乗関数を次のようなϵ許容誤差関数(ϵ-insensitive error function)で置き換える(図7.6)。
Ee(y(x)−t)=⎩⎨⎧0∣y(x)−t∣−ϵ∣y(x)−t∣<ϵother
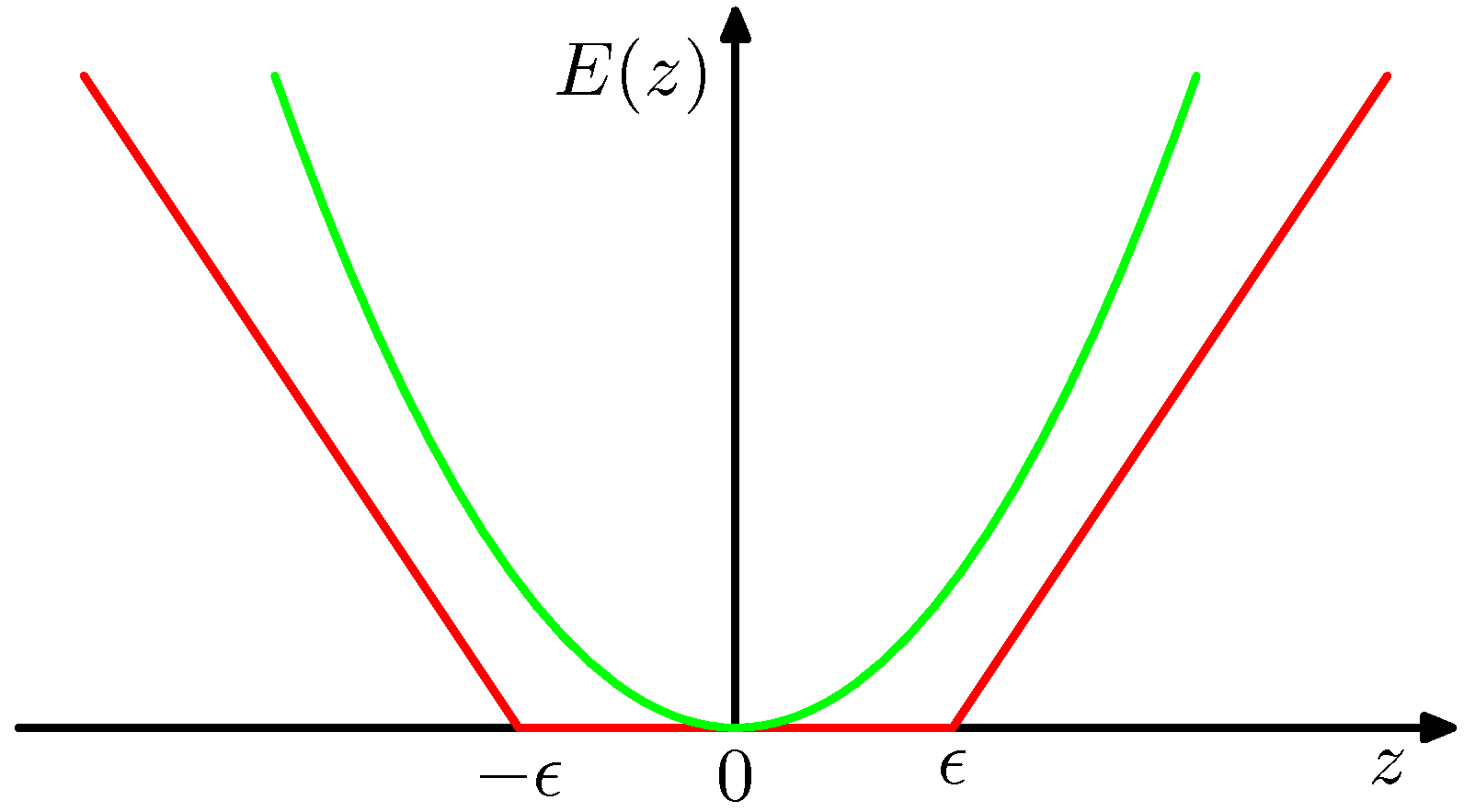
つまり、
Cn=1∑NEe(y(xn)−tn)+21∣∣w∣∣2
を最小にするwをもとめる。
許容誤差関数を使う代わりに、スラック変数を導入して表現する。±ϵのチューブの外側に高いコストを与えるように、ξとξ^を定義する。図に示すように、
tn>y(xn)+ϵ
に対してはξn>0を、
tn<y(xn)+ϵ
に対しては,ξ^n<0を対応させる。
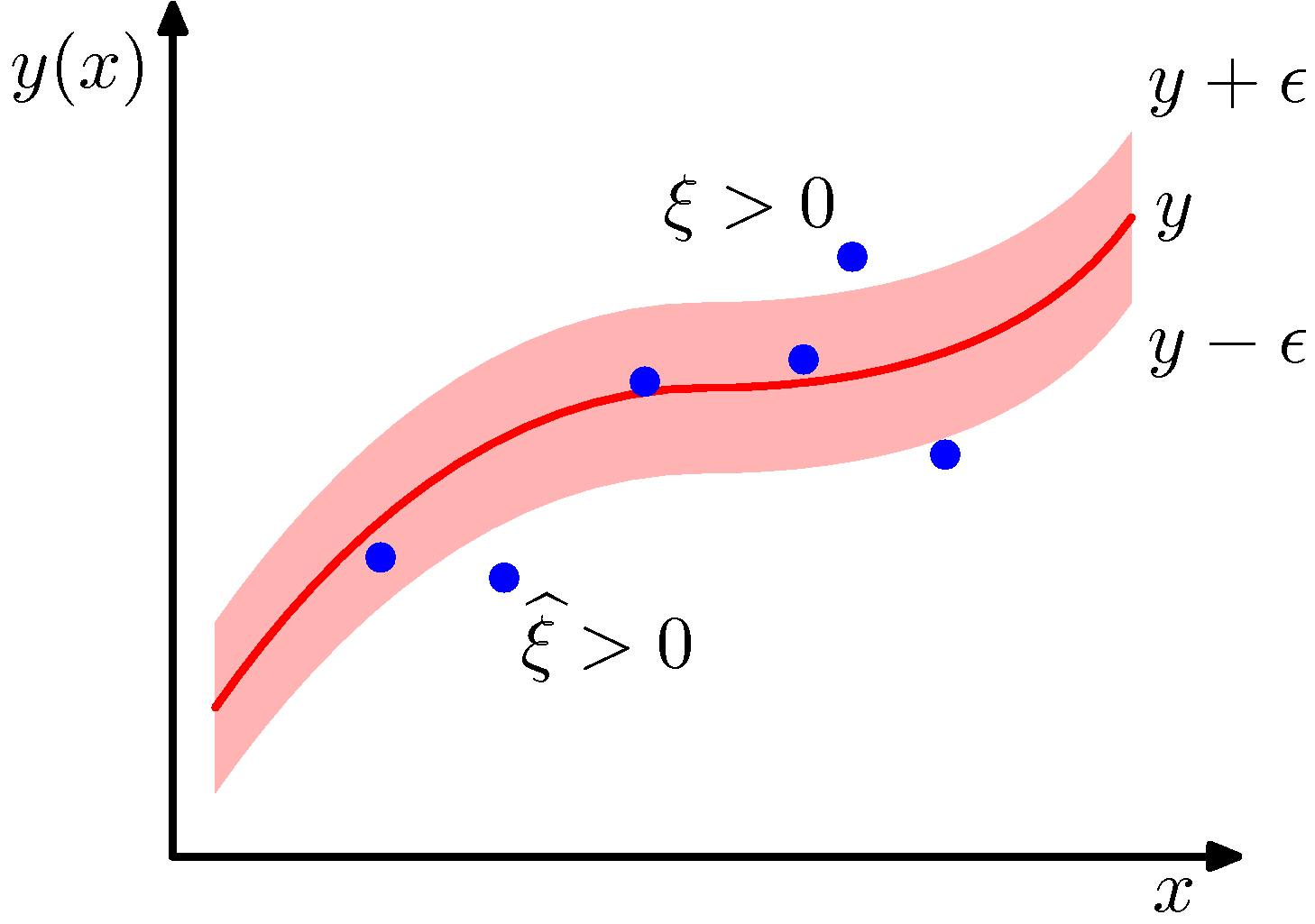
制約条件として
tn≤y(xn)+ϵ+ξn,tn≥y(xn)−ϵ−ξ^n(1)
を課す。このようなスラック変数を用いると、SVRの誤差関数は
Cn=1∑N(ξn+ξ^n)+21∣∣w∣∣2(2)
と表される。また、条件
ξn≥0,ξ^n≥0(3)
も必要である。誤差関数(2)を条件(1)と(3)のもとで最小化する係数を求める。
ラグランジュの未定定数an≥0, a^n≥0, μ≥0, μ^≥0を使って
L=Cn=1∑N(ξn+ξ^n)+21∣∣w∣∣−n=1∑Nan(ϵ+ξn+yn−tn)−n=1∑Na^n(ϵ+ξ^n+yn−tn)
の極値問題を解く。極値条件は
∂w∂L=0よりw=n=1∑N(an−a^n)ϕ(xn)(4)
∂b∂L=0よりn=1∑N(an−a^n)=0(5)
∂ξn∂L=0よりan+μ^n=0(6)
∂ξ^n∂L=0よりa^n+μ^n=0(7)
これらの条件を用いてLを変形すると、{an}と{a^n}を変数としたLの極値問題に帰着できる。
C∑(ξn+ξ^n)−∑(μnξn+μ^nξ^n)−∑anξn−∑a^nξ^n=0
∣∣ω∣∣2=n=1∑Nm=1∑N(an−a^n)(am−a^m)k(xn,xm)
であるから
L^(a,a^)=−21n=1∑Nm=1∑N(an−a^n)(am−a^m)k(xn,xm)−ϵn=1∑N(an+a^n)+n=1∑N(an−a^n)tn(8)
ここで、カーネルの定義
k(xn,x′m)=ϕ(x)Tϕ(x′)(9)
を用いた。
an≥0, a^n≥0とμn≥0, μ^n≥0および(6),(7)の条件を合わせると矩形制約(box constraint)
0≤an≤C,0≤a^n≤C
が成り立つ。これと(5)式の条件のもとでLを最大にする問題になる。
得られたan, a^nから、予測値は
y(x)=n=1∑N(an−a^n)k(x,xn)+b(10)
により計算される。
不等式制約下での極値条件(KKT条件)、つまりラグランジュ未定乗数と対応する制約式の積がゼロという条件は
an(ϵ+ξn+yn−tn)=0(11)
a^n(ϵ+ξ^n+yn−tn)=0(12)
(C−an)ξn=0(13)
(C−a^n)ξ^n=0(14)
これらの式から、anがゼロ以外の値をとるのは、()の中がゼロのとき、すなわちデータ点がチューブの上境界上か外側上にあるときであり、a^nがゼロでないのは、チューブの下境界上か外側下にある場合である。
また、この2つが同時に成り立つことはないので、すべてのデータ点xnに対してan, a^nのどちらかはゼロである。
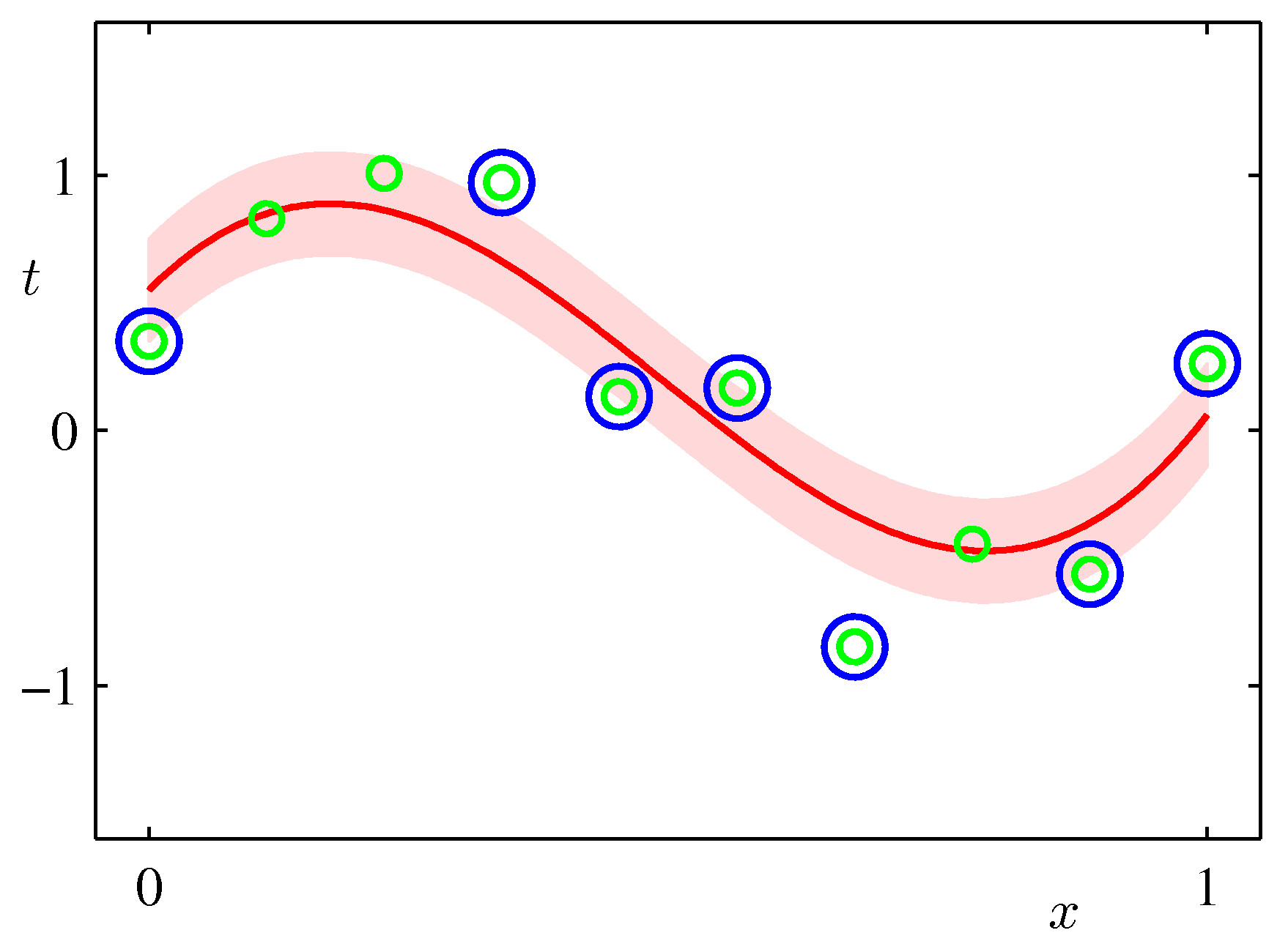
よって、予測に寄与するのは、チューブの外側の点である。つまり、チューブの外側の点がサポートベクトルであるといえる。データが非常にばらついていて、チューブの外のデータ点がたくさんあるときはあまり良い推定が得られない(と思う。かえって線形回帰の方が良い場合もあるだろう)。
パラメータbについて
0<an<Cのとき、(11)よりξn=0。(11)式よりϵ+yn−tn=0である。これを
y(x)=ωTϕ(x)+b(テキストでは(7.1)b=tn−ϵ−ωTϕ(x)=tn−ϵ−m=1∑N(am−a^m)k(xn,xm)
が得られる。実際には、このようにして得られたbの平均値を用いる。
チューブの幅ϵはパラメータであるが、これの代わりに、チューブの外にあるデータ数の割合の上限νを指定する方法もある。(Scholkoph, et.al. (2000))
パラメータν, Cは交差検定によりセットすることが多い。
scikit-learnでは、グリッドサーチやランダムサーチにより決定している。