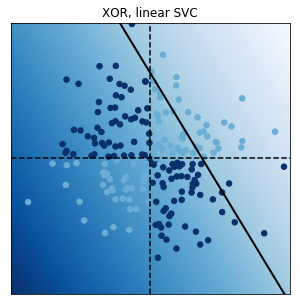
In [14]:
# サンプルデータの作製
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# 平面上で適当に200個の点を選ぶ 座標値(x,y)の200個の組 X[200,2]
X = np.random.randn(200, 2)
# ターゲットt[x[i],y[i]]の値を x[i]+ y[i] > 1 のときtrue, それ以外 false => それデータとしてtrue or falseの境界をsvcで見つける
# 右辺の評価式がtrueかfalseかを配列としてyに与える (ここでは200個の一次元は配列)
y = X[:, 0] + X[:, 1] > 1
# 位置をランダムに動かす: 練習として試してみよう
noise = (np.random.rand(200,2)-0.5)*2.5
X = X + noise
# We display the points with their true labels.
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
cmap = plt.cm.PiYG # Blues
ax.scatter(X[:, 0], X[:, 1],
s=50, c=.5 + .5 * y, # c, edgecolorは色指定, cmapは色調の指定
edgecolors='k',
lw=1, cmap=cmap,
vmin=0, vmax=1)
Out[14]:
<matplotlib.collections.PathCollection at 0x7f3fccbd87c0>